1. EigenPro for Regression and Classification¶
EigenPro iteration [MB17] is a very efficient implementation of kernel regression/classification that uses an optimization method based on preconditioned stochastic gradient descent. It essentially implements a “ridgeless” kernel regression. Regularization, when necessary, can be achieved by early stopping.
Optimization parameters, such as step size, batch size, and the size of the preconditioning block are chosen automatically and optimally. (They can also be set up manually.) This results in a simple and user-friendly interface.
Next, we present several experimental results using a server equipped with one
Intel Xeon E5-1620 CPU.
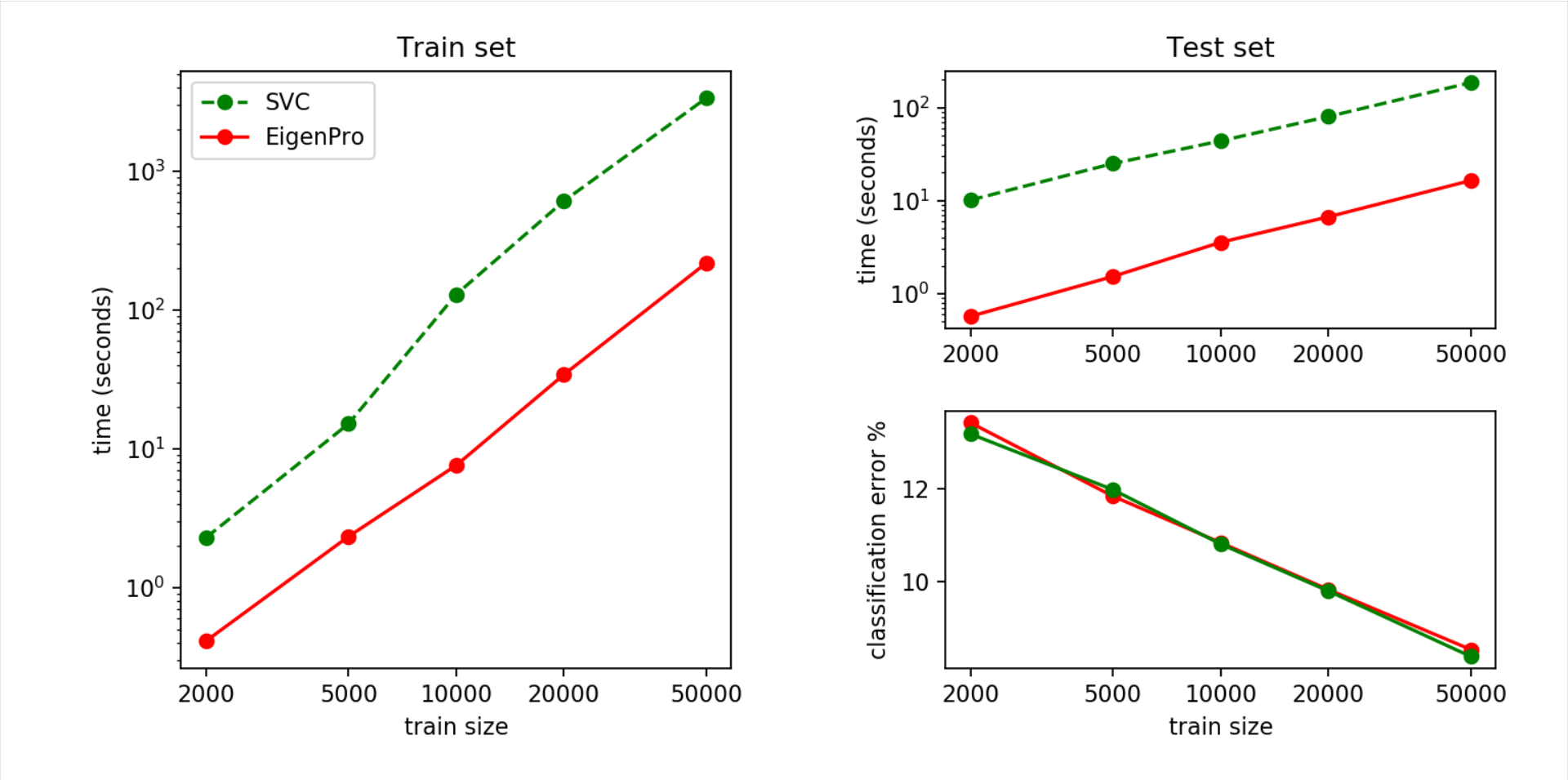
The figure below compares the EigenPro Classifier and the Support Vector
Classifier (SVC) on MNIST digits classification task.
We see that EigenPro and SVC give competitive and similar accuracy on test set.
Notably, on the full MNIST training and testing using EigenPro are
approximately 2 times and 5 times faster than that using SVC, respectively.
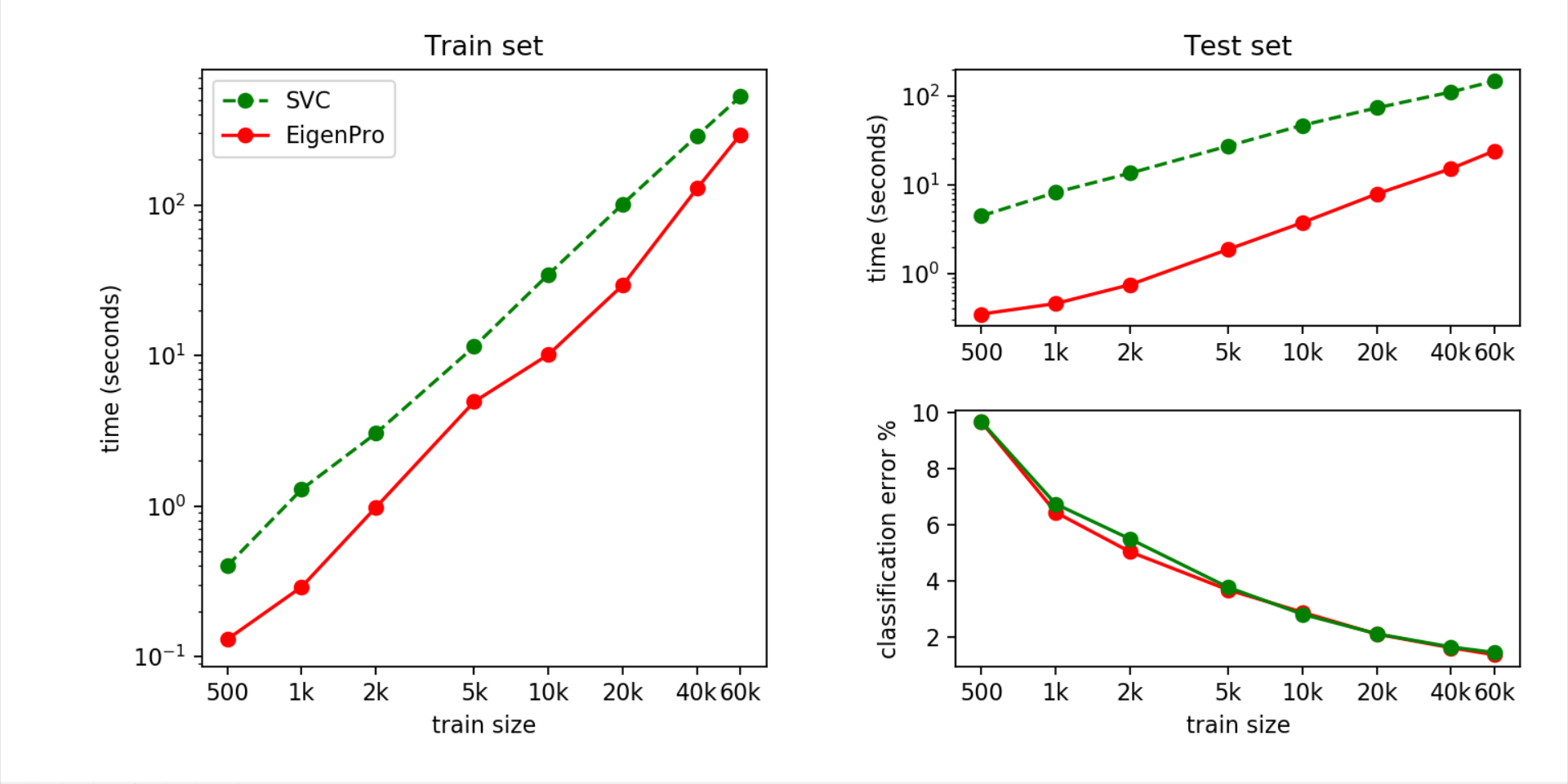
We then repeat the same experiments on MNIST with added label noise. Specifically, we randomly reset the label (0-9) of 20% samples. We see that EigenPro has a significant advantage over SVC on this noisy MNIST. Training and testing using EigenPro are both 10 to 20 times faster than they are when using SVC.
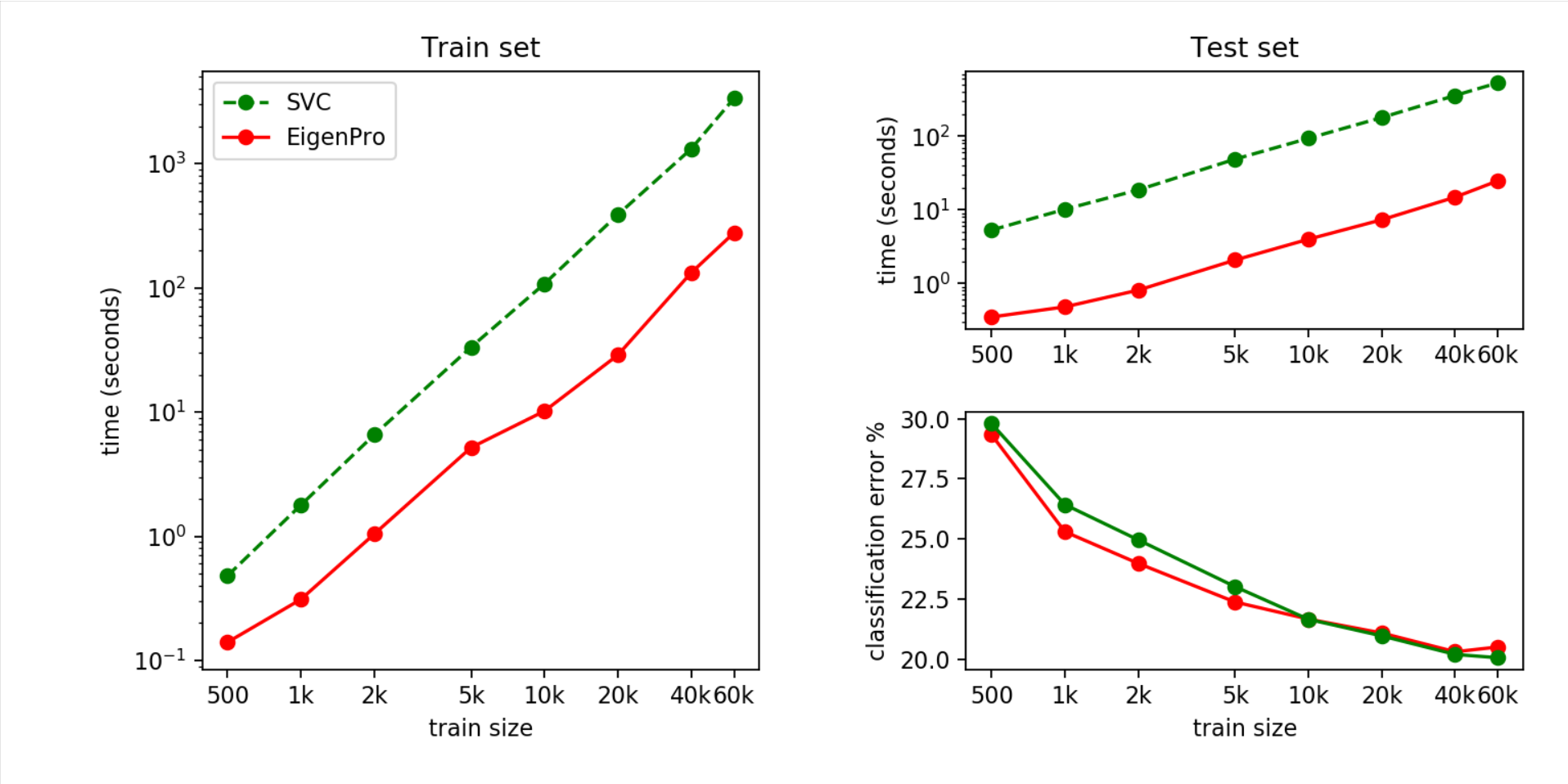
The next figure compares the two methods on a binary classification problem with 400 synthetic features. Again, EigenPro demonstrates 10~20 times acceleration on training and testing without loss of accuracy.